multimodal#
Lernen Sie, wie Sie LLMs zur Verarbeitung von Bildern und Audiodaten einsetzen können.
Visuell#
Durch die vision-Funktion können Sie das Modell Bilder empfangen und Fragen dazu beantworten lassen. In Xinference bedeutet dies, dass bestimmte Modelle in der Lage sind, Bildeingaben zu verarbeiten, wenn sie über die Chat-API kommunizieren.
Unterstützte Modellliste#
In Xinference werden folgende Modelle unterstützt, die die vision-Funktion bereitstellen:
qwen-vl-chat
deepseek-vl-chat
omnilmm
cogvlm2
MiniCPM-Llama3-V 2.5
glm-edge-v
Schnellstart#
Das Modell kann Bilder auf zwei Hauptwegen abrufen: durch Übermitteln eines Bildlinks oder direkt durch Übermitteln eines base64-kodierten Bildes in der Anfrage.
Beispiel für die Verwendung des OpenAI-Clients#
import openai
client = openai.Client(
api_key="cannot be empty",
base_url=f"http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1"
)
response = client.chat.completions.create(
model="<MODEL_UID>",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": "http://i.epochtimes.com/assets/uploads/2020/07/shutterstock_675595789-600x400.jpg",
},
},
],
}
],
)
print(response.choices[0])
Laden Sie ein Base64-kodiertes Bild hoch.#
import openai
import base64
# Function to encode the image
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Path to your image
image_path = "path_to_your_image.jpg"
# Getting the base64 string
b64_img = encode_image(image_path)
client = openai.Client(
api_key="cannot be empty",
base_url=f"http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1"
)
response = client.chat.completions.create(
model="<MODEL_UID>",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{b64_img}",
},
},
],
}
],
)
print(response.choices[0])
Begrenzen Sie die Anzahl der Bilder pro Gesprächsrunde.#
Bei visuellen Modellen, die das VLLM-Backend verwenden, können Sie über den Parameter limit_mm_per_prompt die Anzahl der Bilder begrenzen, die pro Dialogrunde verarbeitet werden können. Dies hilft, die Speichernutzung zu kontrollieren und die Leistung zu verbessern.
# Launch model with image count limitation using Python client
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
# Launch model and set maximum 4 images per conversation turn
model_uid = client.launch_model(
model_name="qwen2.5-vl-instruct",
model_engine="vLLM",
model_format="pytorch",
quantization="none",
model_size_in_billions=3,
limit_mm_per_prompt="{\"image\": 4}"
)
Alternativ kannst du das Modell über die Befehlszeile starten:
# Launch model with image count limitation using CLI
xinference launch \
--model-engine vLLM \
--model-name qwen2.5-vl-instruct \
--size-in-billions 3 \
--model-format pytorch \
--quantization none \
--limit_mm_per_prompt "{\"image\":4}"
Für die Web-UI können Sie den Parameter limit_mm_per_prompt im vLLM-Engine-Formular festlegen:
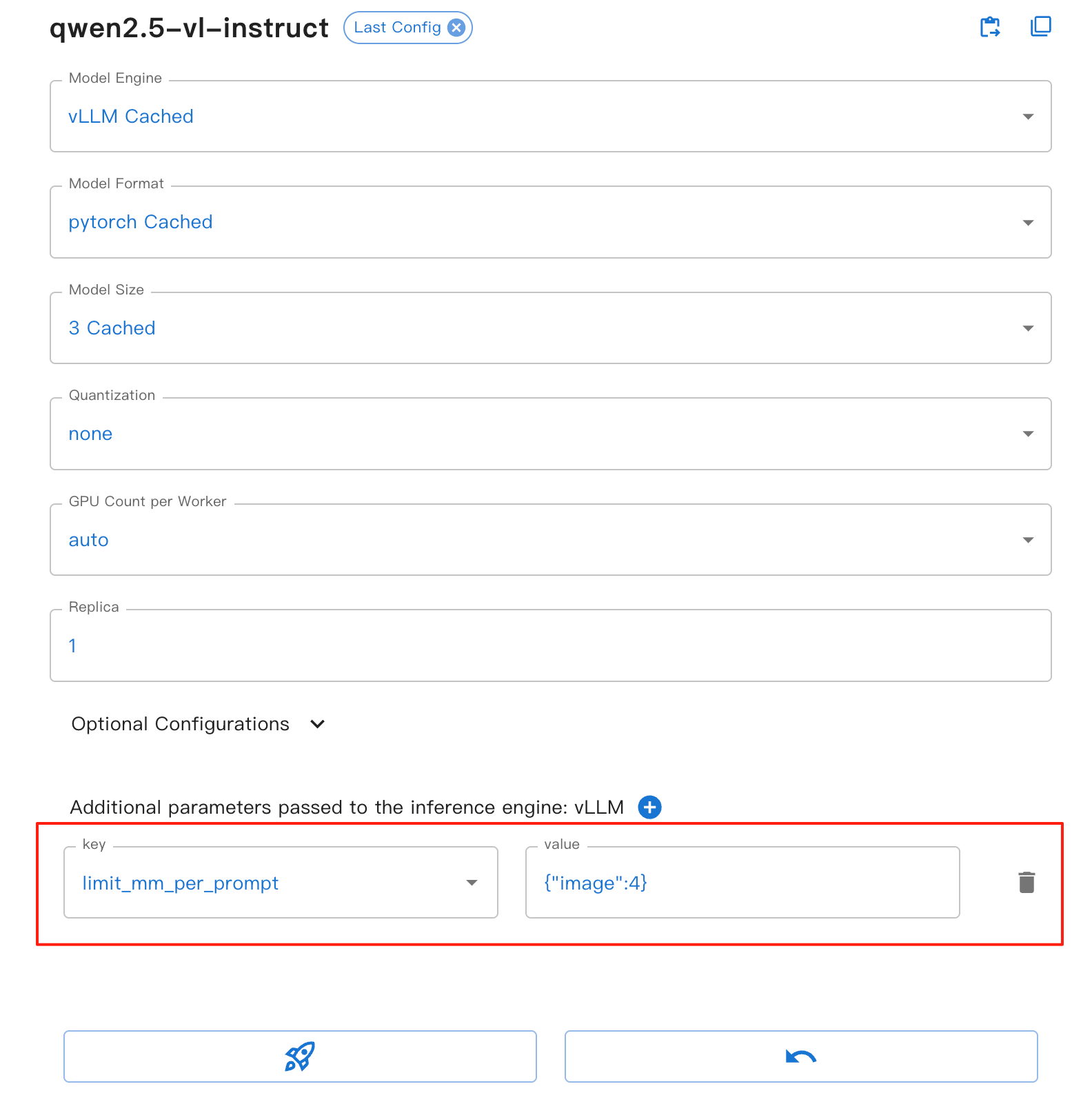
Dieser Parameter bietet die folgenden Vorteile:
image: Legt die maximale Anzahl erlaubter Bilder pro Dialogrunde fest.
Hilft, Speicherüberläufe zu vermeiden, insbesondere bei der Verarbeitung mehrerer Bilder.
Verbesserung der Stabilität und Leistung von Modellinferenzen
Gilt für alle auf VLLM basierenden visuellen Modelle.
Bemerkung
Der Parameter limit_mm_per_prompt ist nur wirksam, wenn das VLLM-Backend verwendet wird. Wenn Ihr Modell ein anderes Backend verwendet, wird dieser Parameter ignoriert.
Weitere Beispiele zu den vision-Fähigkeiten findest du im Tutorial-Notebook.
Lernen Sie die visuellen Fähigkeiten von LLM anhand des Beispiels von qwen-vl-chat kennen.
Audio#
Durch die „Audio“-Funktion kann Ihr Modell Audio empfangen und Audioanalysen durchführen oder basierend auf Sprachbefehlen direkt Textantworten generieren. In Xinference bedeutet dies, dass bestimmte Modelle bei der Kommunikation über die Chat-API in der Lage sind, Audio-Eingaben zu verarbeiten.
Unterstützte Modellliste#
Die Funktion „Audio“ unterstützt in Xinference die folgenden Modelle:
Schnellstart#
Audio kann dem Modell auf zwei wesentliche Arten bereitgestellt werden: durch Übergabe eines Bildlinks oder durch direkte Übergabe einer Audio-URL in der Anfrage.
Chat mit Audio#
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model(<MODEL_UID>)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": [
{
"type": "audio",
"audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/glass-breaking-151256.mp3",
},
{"type": "text", "text": "What's that sound?"},
],
},
{"role": "assistant", "content": "It is the sound of glass shattering."},
{
"role": "user",
"content": [
{"type": "text", "text": "What can you do when you hear that?"},
],
},
{
"role": "assistant",
"content": "Stay alert and cautious, and check if anyone is hurt or if there is any damage to property.",
},
{
"role": "user",
"content": [
{
"type": "audio",
"audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/1272-128104-0000.flac",
},
{"type": "text", "text": "What does the person say?"},
],
},
]
print(model.chat(messages))