Traditionelles maschinelles Lernmodell (experimentell)#
Erfahren Sie, wie Sie mit Xinference traditionelle Machine-Learning-Modelle inferieren. In Xinference werden diese flexiblen und erweiterbaren Modelle als Flexible Modelle bezeichnet.
Added in version v1.7.1: Diese Funktion ist seit Version v1.7.1 öffentlich verfügbar. Die API ist derzeit noch nicht stabil und kann in zukünftigen Iterationen Änderungen unterliegen.
Introduktion#
Traditionelle maschinelle Lernmodelle können im Ökosystem, das von großen Modellen dominiert wird, weiterhin eine wichtige Rolle spielen.
Xinference bietet flexible Erweiterungsmöglichkeiten für die Inferenz traditioneller Machine-Learning-Modelle. Es unterstützt nativ das Laden und Ausführen der folgenden Modelltypen:
Die Verwendung von HuggingFace Pipelines für Modelle, die auf HuggingFace gehostet werden, ist für Aufgaben wie Klassifikation geeignet.
Verwenden Sie die ModelScope Pipeline für Modelle auf ModelScope, die für Klassifizierungs- und andere Aufgaben geeignet ist.
YOLO wird für die Bilderkennung und verwandte Computer-Vision-Aufgaben verwendet.
Xinference unterstützt eine Vielzahl traditioneller Machine-Learning-Modelle. Für jede der oben genannten Kategorien zeigen wir anhand eines repräsentativen Beispiels Schritt für Schritt, wie Rückschlüsse auf der Xinference-Plattform durchgeführt werden können.
Eingebaute Modellunterstützungsfälle#
HuggingFace Pipeline Model#
Zunächst nehmen wir als Beispiel das Modell FacebookAI/roberta-large-mnli. Dieses Modell gehört zur Kategorie der Zero-Shot-Klassifikationsmodelle. Für andere Modelltypen muss bei der Registrierung lediglich die entsprechende Aufgabe angegeben werden (ebenfalls ein Parameter der Pipeline).
Laden Sie das Modell in den folgenden Pfad herunter:
/path/to/roberta-large-mnli
Als nächstes zeigen wir, wie man das flexible Modell in der Xinference Web UI registriert. In den folgenden Beispielen werden wir, sofern nicht erforderlich, die Benutzeroberflächenoperationen überspringen und uns auf die Kernlogik konzentrieren.
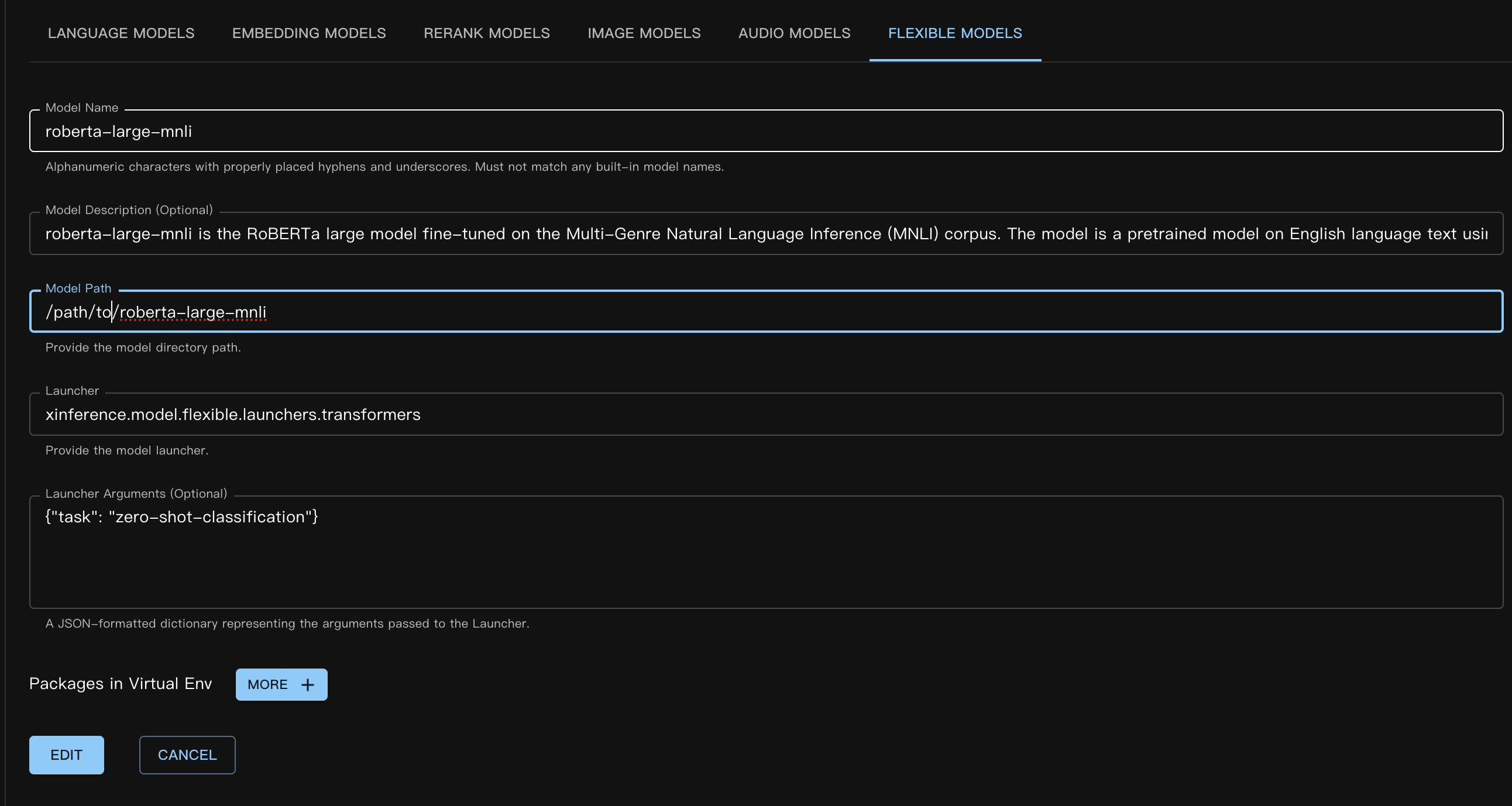
Das entsprechende benutzerdefinierte Modell-JSON lautet wie folgt:
{
"model_name": "roberta-large-mnli",
"model_id": null,
"model_revision": null,
"model_hub": "huggingface",
"model_description": "roberta-large-mnli is the RoBERTa large model fine-tuned on the Multi-Genre Natural Language Inference (MNLI) corpus. The model is a pretrained model on English language text using a masked language modeling (MLM) objective.",
"model_uri": "/path/to/roberta-large-mnli",
"launcher": "xinference.model.flexible.launchers.transformers",
"launcher_args": "{\"task\": \"zero-shot-classification\"}",
"virtualenv": {
"packages": [],
"inherit_pip_config": true,
"index_url": null,
"extra_index_url": null,
"find_links": null,
"trusted_host": null,
"no_build_isolation": null
},
"is_builtin": false
}
Siehe Abschnitt register_custom_model für Informationen zur Registrierung eines Modells über Code oder Kommandozeile.
Wählen Sie anschließend in der Web-Benutzeroberfläche Modell starten / Benutzerdefiniertes Modell / Flexibles Modell aus, um das Modell zu laden. Der Ladevorgang ist identisch mit dem anderer Modelltypen.
Wenn Sie die Befehlszeile verwenden, denken Sie daran, den Parameter --model-type flexible anzugeben.
Nach erfolgreichem Laden des Modells können wir die Inferenz auf folgende Weise durchführen.
curl -X 'POST' \
'http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1/flexible/infers' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "roberta-large-mnli",
"args": [
"one day I will see the world",
["travel", "cooking", "dancing"]
]
}'
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("roberta-large-mnli")
sequence_to_classify = "one day I will see the world"
candidate_labels = ['travel', 'cooking', 'dancing']
model.infer(sequence_to_classify, candidate_labels)
{"sequence":"one day I will see the world","labels":["travel","cooking","dancing"],"scores":[0.9799638986587524,0.010605016723275185,0.009431036189198494]}
ModelScope Pipeline Model#
ModelScope Pipeline Modelle sind den Huggingface Modellen sehr ähnlich, der einzige Unterschied liegt in der verwendeten Launcher-Implementierung.
Wir nehmen als Beispiel ein Zero-Shot-Klassifikationsmodell von ModelScope. Das Modell ist iic/nlp_structbert_zero-shot-classification_chinese-base.
Hier haben wir die Funktion der virtuellen Modellumgebung von Xinference verwendet. Da das in diesem Beispiel verwendete Modell transformers==4.50.3 benötigt, um ordnungsgemäß zu funktionieren. Zur Isolierung der Ausführungsumgebung haben wir bei der Modellregistrierung virtuelle Umgebung verwendet.
Die Syntax zur Angabe benutzerdefinierter Pakete bei der Modellregistrierung ist dieselbe wie bei normalen Paketen, es gibt jedoch einige Sonderfälle. Da die virtuelle Umgebung weiterhin auf den site-packages des von Xinference ausgeführten Python-Interpreters basiert, müssen wir explizit #system_numpy# einfügen. Der Paketname wird mit #system_xx# umschlossen, um sicherzustellen, dass die virtuelle Umgebung bei der Erstellung mit der Basisumgebung übereinstimmt, da sonst leicht Laufzeitfehler auftreten können.
Registrierungsmethode (Web UI):
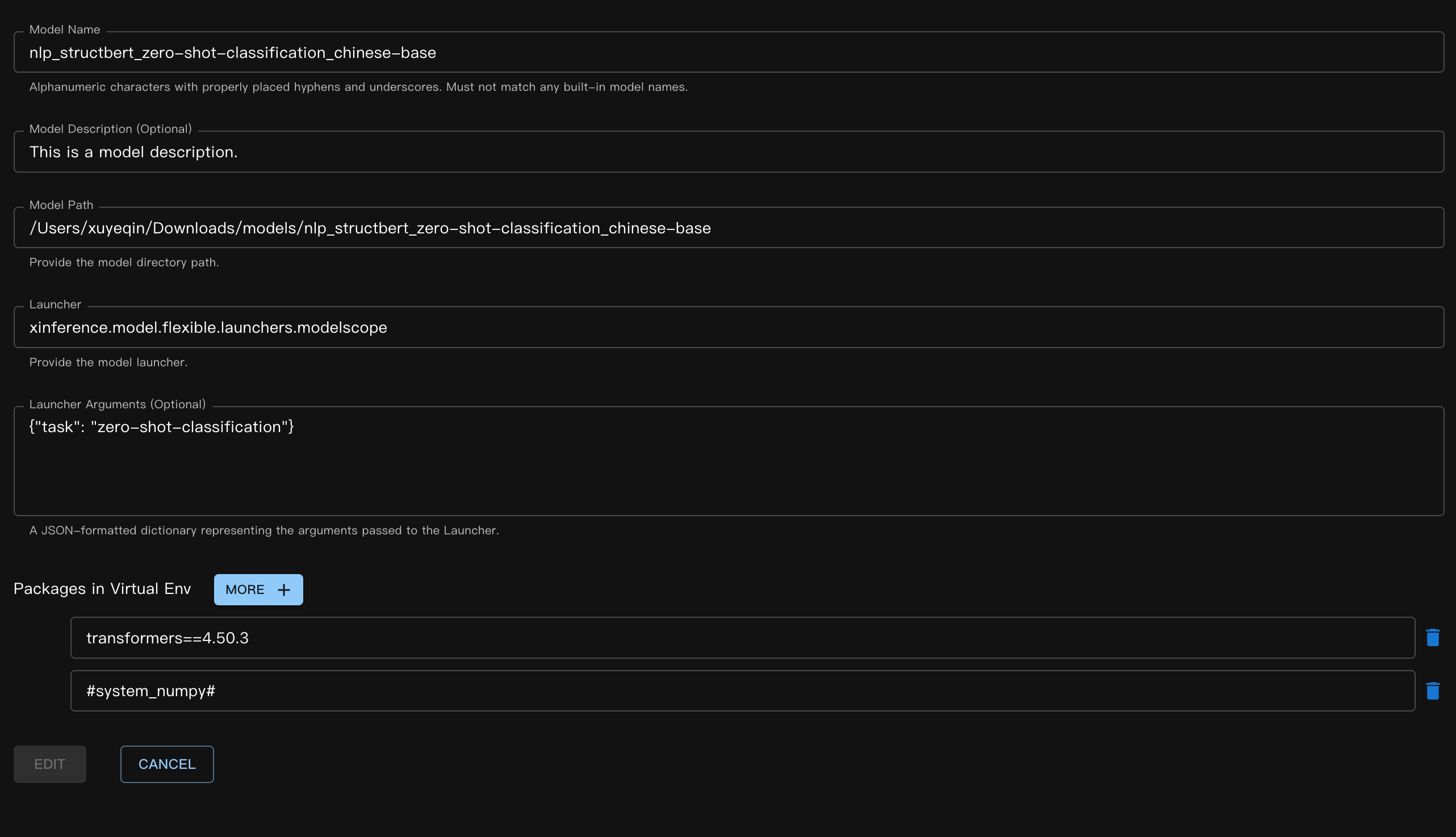
Entsprechende JSON-Datei:
{
"model_name": "nlp_structbert_zero-shot-classification_chinese-base",
"model_id": null,
"model_revision": null,
"model_hub": "huggingface",
"model_description": "This is a model description.",
"model_uri": "/Users/xuyeqin/Downloads/models/nlp_structbert_zero-shot-classification_chinese-base",
"launcher": "xinference.model.flexible.launchers.modelscope",
"launcher_args": "{\"task\": \"zero-shot-classification\"}",
"virtualenv": {
"packages": [
"transformers==4.50.3",
"#system_numpy#"
],
"inherit_pip_config": true,
"index_url": "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple",
"extra_index_url": null,
"find_links": null,
"trusted_host": null,
"no_build_isolation": null
},
"is_builtin": false
}
Modell-Inferenz
curl -X 'POST' \
'http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1/flexible/infers' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "nlp_structbert_zero-shot-classification_chinese-base",
"args": [
"世界那么大,我想去看看"
],
"candidate_labels": ["家居", "旅游", "科技", "军事", "游戏", "故事"]
}'
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("nlp_structbert_zero-shot-classification_chinese-base")
labels = ['家居', '旅游', '科技', '军事', '游戏', '故事']
sentence = '世界那么大,我想去看看'
model.infer(sentence, candidate_labels=labels)
{"labels":["旅游","故事","游戏","家居","科技","军事"],"scores":[0.5115892291069031,0.1660086065530777,0.11971458047628403,0.08431519567966461,0.06298774480819702,0.05538458004593849]}%
YOLO#
YOLO ist ein bekanntes Echtzeit-Objektmodell, das in Bilderkennung und Videoanalyse weit verbreitet ist.
Laden Sie zuerst die YOLO-Gewichte herunter. Hier verwenden wir als Beispiel die Datei yolov11s.pt.
Modell-Definitions-JSON-Datei:
{
"model_name": "yolo11s",
"model_id": null,
"model_revision": null,
"model_hub": "huggingface",
"model_description": "YOLO is a popular real-time object detection model, widely used in image detection and video analysis scenarios.",
"model_uri": "/Users/xuyeqin/Downloads/models/yolo11s.pt",
"launcher": "xinference.model.flexible.launchers.yolo",
"launcher_args": "{}",
"virtualenv": {
"packages": [
"ultralytics",
"#system_numpy#"
],
"inherit_pip_config": true,
"index_url": "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple",
"extra_index_url": null,
"find_links": null,
"trusted_host": null,
"no_build_isolation": null
},
"is_builtin": false
}
Modell-Inferenz
import requests
from PIL import Image
import io
import base64
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("yolo11s")
url = "https://ultralytics.com/images/bus.jpg"
response = requests.get(url)
response.raise_for_status()
img = Image.open(io.BytesIO(response.content))
buffered = io.BytesIO()
img.save(buffered, format="JPEG")
img_bytes = buffered.getvalue()
img_base64 = base64.b64encode(img_bytes).decode('utf-8')
model.infer(source=img_base64)
[[{'name': 'bus',
'class': 5,
'confidence': 0.93653,
'box': {'x1': 13.9521, 'y1': 227.0665, 'x2': 800.17688, 'y2': 739.13965}},
{'name': 'person',
'class': 0,
'confidence': 0.89741,
'box': {'x1': 669.89709,
'y1': 389.82065,
'x2': 809.58966,
'y2': 879.65491}},
{'name': 'person',
'class': 0,
'confidence': 0.88205,
'box': {'x1': 52.37262, 'y1': 397.83792, 'x2': 248.506, 'y2': 905.98212}},
{'name': 'person',
'class': 0,
'confidence': 0.8706,
'box': {'x1': 222.58685,
'y1': 405.93442,
'x2': 345.02032,
'y2': 859.52789}},
{'name': 'person',
'class': 0,
'confidence': 0.66505,
'box': {'x1': 0.28522, 'y1': 548.60931, 'x2': 81.25904, 'y2': 871.59076}}]]
Schreiben Sie ein benutzerdefiniertes flexibles Modell.#
Zunächst implementieren wir einen einfachen benutzerdefinierten Launcher für die Sentimentbewertung. In diesem Beispiel verwenden wir keine tatsächlichen Modellgewichte, daher führt die load-Funktion keinerlei Modellladungsoperationen aus.
# my_flexible_model.py
from xinference.model.flexible import FlexibleModel
class RuleBasedSentimentModel(FlexibleModel):
def load(self):
self.pos_words = self.config.get("pos", ["good", "happy", "great"])
self.neg_words = self.config.get("neg", ["bad", "sad", "terrible"])
def infer(self, text: str):
score = 0
words = text.lower().split()
for w in words:
if w in self.pos_words:
score += 1
elif w in self.neg_words:
score -= 1
return {"score": score}
def launcher(model_uid: str, model_spec: FlexibleModel, **kwargs) -> FlexibleModel:
# get model path,
# in this example, we do not use it, so it's empty
model_path = model_spec.model_uri
return RuleBasedSentimentModel(model_uid=model_uid, model_path=model_path, config=kwargs)
Das Modell JSON ist wie folgt definiert:
{
"model_name": "my-flexible-model",
"model_id": null,
"model_revision": null,
"model_hub": "huggingface",
"model_description": "This is a model description.",
"model_uri": "/path/to/model",
"launcher": "my_flexible_model.launcher",
"launcher_args": "{\"pos\": [\"good\", \"happy\", \"great\", \"nice\"]}",
"virtualenv": {
"packages": [],
"inherit_pip_config": true,
"index_url": null,
"extra_index_url": null,
"find_links": null,
"trusted_host": null,
"no_build_isolation": null
},
"is_builtin": false
}
Hier haben wir das Modell durch die Übergabe eines benutzerdefinierten pos-Werts erweitert.
Schließlich überprüfen wir das Ergebnis:
from xinference.client import Client
client = Client("http://127.0.0.1:9997")
model = client.get_model("my-flexible-model")
model.infer("I feel nice and am happy today")
{'score': 2}
Schlussfolgerung#
Der flexible Modell-Launcher von Xinference ist auf Github zu finden. Beiträge zur Unterstützung weiterer traditioneller maschineller Lernmodelle sind willkommen!