Inferenz-Engine#
Xinference unterstützt für verschiedene Modelle unterschiedliche Inferenz-Engines. Nachdem der Benutzer ein Modell ausgewählt hat, wählt Xinference automatisch die passende Engine aus.
llama.cpp#
Xinference unterstützt derzeit das von Xinference-Team entwickelte xllamacpp als llama.cpp-Backend. llama.cpp basiert auf der Tensor-Bibliothek ggml und unterstützt die Inferenz von LLaMA-Serienmodellen und deren Varianten.
Warnung
Seit Xinference v1.5.0 ist xllamacpp die Standardoption für llama.cpp, llama-cpp-python ist veraltet; ab Xinference v1.6.0 wurde llama-cpp-python entfernt.
Bitte lesen Sie die Parametereinstellungen in der common_params-Strukturdefinition in der common.h von llama.cpp nach.
Es kann Parameter mit mehreren Verschachtelungsebenen geben. Zum Beispiel sampling.top_k. Bitte verwenden Sie ., um verschachtelte Parameter zu trennen.
Hier ist ein Beispiel für die Einstellung der verschachtelten Sampling-Parameter in der WebUI:
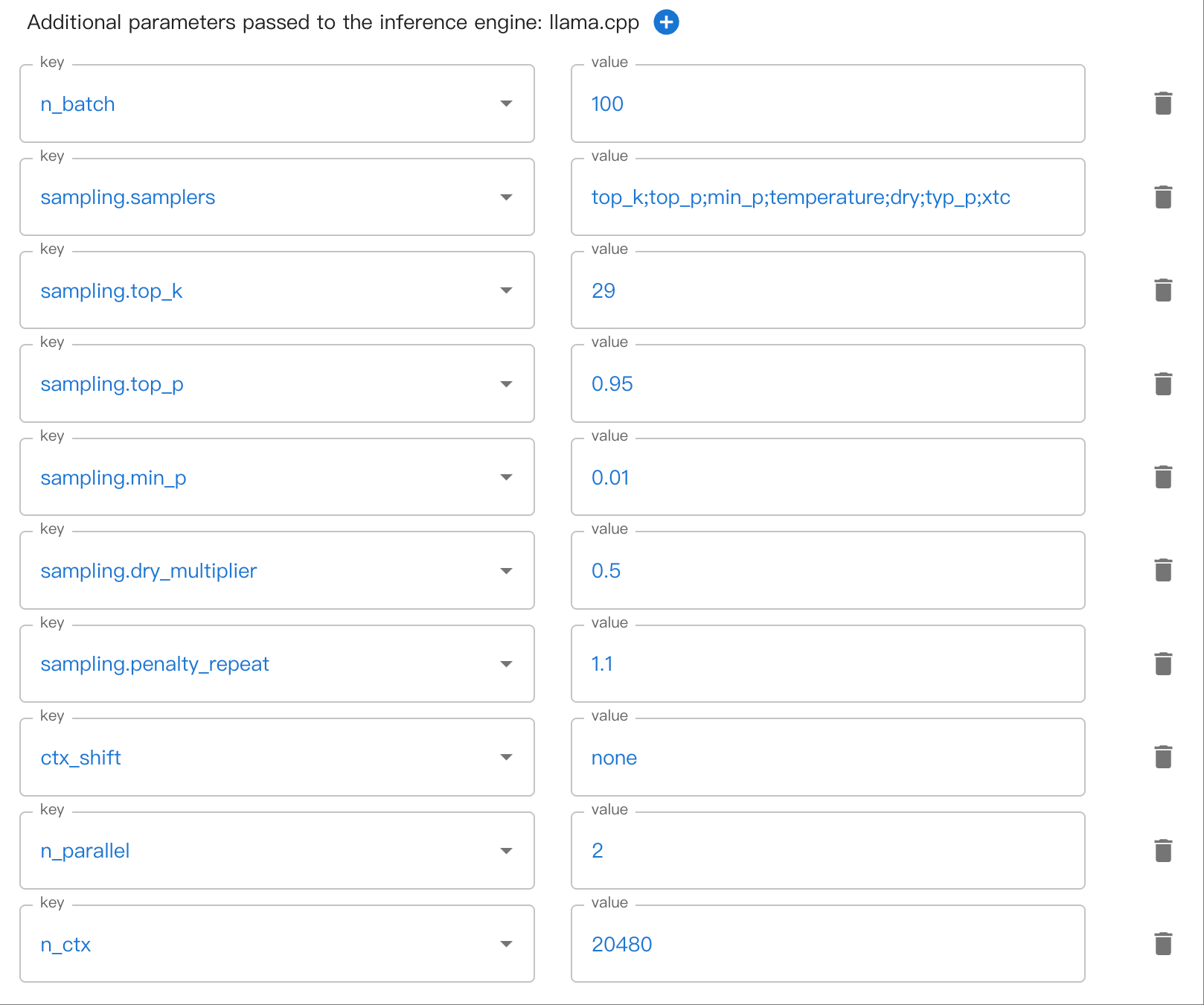
Auto NGL#
Added in version v1.6.1: Seit v1.6.1 wird die GPU-Layer-Schätzung automatisch aktiviert, wenn n-gpu-layers nicht angegeben ist (Standard: -1).
Diese Funktion kann die Anzahl der GPU-Layer (NGL) automatisch für das llama.cpp-Backend festlegen. Beachten Sie, dass dies keine präzise Berechnung ist, daher ist das -ngl-Ergebnis möglicherweise nicht optimal, und es können weiterhin Fehler aufgrund unzureichenden Videospeichers auftreten.
Derzeit gibt es keine offizielle Unterstützung für automatisches NGL. Weitere Informationen findest du im folgenden Issue:
Unsere Implementierung basiert auf Ollamas automatischem NGL, weist jedoch einige Unterschiede auf:
Wir verwenden die Geräteinformationen, die von xllamacpp bereitgestellt werden.
Wir haben die Unterstützung für einige ungewöhnliche Architekturen entfernt, bei denen die Standardberechnungslogik verwendet wurde.
Wenn das automatische NGL fehlschlägt, versuchen wir, alles auf die GPU zu laden.
Wir unterstützen keine GGUF-Modelle mit eingebetteten multimodalen Projektoren. Dieses Format befindet sich derzeit noch in der Experimentierphase.
Häufig gestellte Fragen#
Server error: {‚code‘: 500, ‚message‘: ‚failed to process image‘, ‚type‘: ‚server_error‘}
Server-Logs:
encoding image or slice... slot update_slots: id 0 | task 0 | kv cache rm [10, end) srv process_chun: processing image... ggml_metal_graph_compute: command buffer 0 failed with status 5 error: Internal Error (0000000e:Internal Error) clip_image_batch_encode: ggml_backend_sched_graph_compute failed with error -1 failed to encode image srv process_chun: image processed in 2288 ms mtmd_helper_eval failed with status 1 slot update_slots: id 0 | task 0 | failed to process image, res = 1
Möglicherweise verursacht durch unzureichenden Speicher. Du kannst versuchen,
n_ctxzu verringern, um das Problem zu beheben.Server error: {‚code‘: 400, ‚message‘: ‚the request exceeds the available context size. try increasing the context size or enable context shift‘, ‚type‘: ‚invalid_request_error‘}
Wenn Sie die Multimodal-Funktion verwenden, ist
ctx_shiftstandardmäßig deaktiviert. Versuchen Sie,n_ctxzu erhöhen odern_parallelzu verringern, um die Kontextgröße pro Slot zu vergrößern.Server error: {‚code‘: 500, ‚message‘: ‚Input prompt is too big compared to KV size. Please try increasing KV size.‘, ‚type‘: ‚server_error‘}
Server-Logs:
ggml_metal_graph_compute: command buffer 1 failed with status 5 error: Insufficient Memory (00000008:kIOGPUCommandBufferCallbackErrorOutOfMemory) graph_compute: ggml_backend_sched_graph_compute_async failed with error -1 llama_decode: failed to decode, ret = -3 srv update_slots: failed to decode the batch: KV cache is full - try increasing it via the context size, i = 0, n_batch = 2048, ret = -3
Dies kann aufgrund eines fehlgeschlagenen KV-Cache-Aufbaus auftreten. Sie können das Problem lösen, indem Sie
n_ctxverkleinern,n_parallelerhöhen oder den Parametern_gpu_layersanpassen, um einen Teil des Modells auf die GPU zu laden. Beachten Sie, dass eine Erhöhung vonn_parallelkeine Leistungssteigerung bringt, wenn Sie nur serielle Inferenzanfragen verarbeiten.
transformers#
Transformers unterstützt die überwiegende Mehrheit der neu veröffentlichten Modelle. Es ist die Standard-Engine für Modelle im PyTorch-Format.
vLLM#
vLLM ist eine äußerst effiziente und benutzerfreundliche Inferenz-Engine für große Sprachmodelle.
vLLM hat die folgenden Eigenschaften:
Führender Inferenz-Durchsatz
Verwaltung von Attention-Key- und Value-Speichern mit PagedAttention
Kontinuierliches Batch-Processing eingehender Anfragen
Optimierte CUDA-Kernel
Wenn die folgenden Bedingungen erfüllt sind, wählt Xinference automatisch vLLM als Inference-Engine aus:
Das Modellformat ist
pytorch,gptq,awq,fp4,fp8oderbnb.Wenn das Modellformat
pytorchist, muss die Quantisierungsoptionnonesein.Wenn das Modellformat
awqist, muss die QuantisierungsoptionInt4sein.Wenn das Modellformat
gptqist, muss die QuantisierungsoptionInt3,Int4oderInt8sein.Das Betriebssystem ist Linux und es gibt mindestens ein CUDA-fähiges Gerät.
Das
model_family-Feld benutzerdefinierter Modelle und dasmodel_name-Feld integrierter Modelle sind in der Unterstützungsliste von vLLM enthalten.
Derzeit umfassen die unterstützten Modelle:
code-llama,code-llama-instruct,code-llama-python,deepseek,deepseek-chat,deepseek-coder,deepseek-coder-instruct,deepseek-r1-distill-llama,gorilla-openfunctions-v2,HuatuoGPT-o1-LLaMA-3.1,llama-2,llama-2-chat,llama-3,llama-3-instruct,llama-3.1,llama-3.1-instruct,llama-3.3-instruct,minicpm5-1b,tiny-llama,wizardcoder-python-v1.0,wizardmath-v1.0,Yi,Yi-1.5,Yi-1.5-chat,Yi-1.5-chat-16k,Yi-200k,Yi-chatcodestral-v0.1,mistral-instruct-v0.1,mistral-instruct-v0.2,mistral-instruct-v0.3,mistral-large-instruct,mistral-nemo-instruct,mistral-v0.1,openhermes-2.5,seallm_v2Baichuan-M2,codeqwen1.5,codeqwen1.5-chat,deepseek-r1-distill-qwen,DianJin-R1,fin-r1,HuatuoGPT-o1-Qwen2.5,KAT-V1,marco-o1,qwen1.5-chat,qwen2-instruct,qwen2.5,qwen2.5-coder,qwen2.5-coder-instruct,qwen2.5-instruct,qwen2.5-instruct-1m,qwenLong-l1,QwQ-32B,QwQ-32B-Preview,seallms-v3,skywork-or1,skywork-or1-preview,XiYanSQL-QwenCoder-2504llama-3.2-vision,llama-3.2-vision-instructbaichuan-2,baichuan-2-chatInternLM2ForCausalLMqwen-chatmixtral-8x22B-instruct-v0.1,mixtral-instruct-v0.1,mixtral-v0.1cogagentglm-edge-chat,glm4-chat,glm4-chat-1mcodegeex4,glm-4vseallm_v2.5orion-chatqwen1.5-moe-chat,qwen2-moe-instructCohereForCausalLMdeepseek-v2-chat,deepseek-v2-chat-0628,deepseek-v2.5,deepseek-vl2deepseek-prover-v2,deepseek-r1,deepseek-r1-0528,deepseek-v3,deepseek-v3-0324,Deepseek-V3.1,moonlight-16b-a3b-instructdeepseek-r1-0528-qwen3,qwen3minicpm3-4binternlm3-instructgemma-3-1b-itglm4-0414minicpm-2b-dpo-bf16,minicpm-2b-dpo-fp16,minicpm-2b-dpo-fp32,minicpm-2b-sft-bf16,minicpm-2b-sft-fp32,minicpm4Ernie4.5Qwen3-Coder,Qwen3-Instruct,Qwen3-Thinkingglm-4.5,GLM-4.6,GLM-4.7gpt-ossseed-ossQwen3-Next-Instruct,Qwen3-Next-ThinkingDeepSeek-V3.2,DeepSeek-V3.2-ExpMiniMax-M2,MiniMax-M2.5,MiniMax-M2.7GLM-4.7-Flashglm-5,glm-5.1DeepSeek-V4-Flash,DeepSeek-V4-Pro
SGLang#
SGLang verfügt über eine leistungsstarke Inferenz-Laufzeitumgebung basierend auf RadixAttention. Sie beschleunigt die Ausführung komplexer LLM-Programme erheblich, indem sie den KV-Cache automatisch über mehrere Aufrufe hinweg wiederverwendet. Sie unterstützt zudem andere gängige Inferenztechniken wie kontinuierliches Batching und Tensor-Parallelisierung.
MLX#
MLX bietet eine effiziente Möglichkeit, LLMs auf Apple Silicon-Chips auszuführen. Wenn ein Modell im MLX-Format vorliegt, wird Mac-Benutzern mit Apple Silicon-Chips die Verwendung der MLX-Engine empfohlen.